
事象発生日:2020-05-27
記事公開日:2020-05-17
アクセス数:16875
様々な要因があり,バージョン管理システムとしてSubversion (svn) を使っていた所属研究室も,gitへ移行する流れとなった.
それらの環境整備とともに,講習会も開くことになってしまったので,そのための資料である.
svnとの違いを強調した資料になっている,つもり?
GitHubライクで,無料で使えるリポジトリマネージャー,ということで,GitLabを用いているので,それを想定にしている.
また,人工衛星開発と関連研究を主とする研究室なため,ハードウェア開発といった文脈も暗に含まれている.
なお,gitの入門書はネットにあふれているので,ここでは簡単な操作はやったことがある人に対して,gitの内部実体に触れながら仕組みを理解してもらうことで,より良いgitの使い方ができる手助けになることを目指す.
以下を理解していれば,ほぼ全ての操作や方針に納得がいくはず.
(たとえ今回理解できなくても,gitを使い慣れてきたタイミングでもう一度読んで欲しい.)
特に,commitがハッシュの片方向リストであること,branch,tagがcommitへの参照(ref,ポインタ)である,ということが重要(svnと本質的に違う).
| ・ | object | gitのDB(データベース)はkey - vaule型であり,全てのobject(commit, tree, blob)はハッシュ(SHA-1)をkeyにしてアクセスされる. | ||
| ・ | blob | DBに保存されている,バージョン管理対象のファイル(と思って差し支えない). | ||
| ・ | tree | 複数のblobを束ねる.束ねているblobのハッシュ,treeのハッシュを持つ. バージョン管理ファイルのファイル名,ディレクトリ構成などを管理する. | ||
| ・ | commit | parent commitへのハッシュをもつ片方向リスト. 該当バージョンへのスナップショットのrootを指すtreeへのポインタをもつ. 特定のcommitを変更する(=ハッシュが変わる)と連なる子のcommitハッシュも全て変わってしまう(=違うobjectになってしまう).つまり,歴史の改ざんが難しい. | ||
| ・ | ref | objectを指すポインタ.つまり,中身はただのハッシュ. | ||
| ・ | branch | commitへのポインタ | ||
| ・ | tag | 特定のobjcetへの変更不能なポインタ.通常はcommitを指す. | ||
| ・ | HEAD | working directoryにcheckoutされているcommitないしは "branch" を指すポインタ.(なので,branchを指している場合は正確にはこれはハッシュではない.) | ||
| ※ | gitではobjectのkeyがハッシュになっている,つまり,ハッシュをobjectへのポインタとして使っている. |
| ※ | tree, blobについては,単純にgitを使っていても意識しないので,知らなくていいといえば知らなくてもいいが,commitは(treeを通じて)その瞬間のバージョン管理された全てのファイル(≒blob)を指している,ということは重要である. |
| ※ | tagはcommitのハッシュをもつrefと書いたが,正確にはこれは軽量tagの話で,注釈付きtagはtag objectのハッシュをもつrefで,このtag objectがcommitへのハッシュと注釈メッセージを保持する. |
なお,pushとは,現在リモートリポジトリのDBにはない,push対象となるローカルリポジトリのbranchから参照されるobjectをそのDBに追加し,さらにリモートリポジトリの対象branchの参照先を移動する "操作" であり,
fetchとは,リモートリポジトリにある全てのrefから到達可能なobjectのうち,ローカルリポジトリにないものを取得し,さらにローカルリポジトリにあるリモートリポジトリのrefをリモートリポジトリにあわせて更新する "操作" である.
ggればいくらでも入門解説書が存在する(例えば,backlogが運用する「サル先生のGit入門」とか(がいい,と後輩が言っていた))ので,簡単な操作(clone, checkout, add, commit, push, fetch, pull, merge等)についてはやったことがある(or 知っている)ことを前提にする.
(あと,(gitではなく)一般的なハッシュの意味も知っていて欲しい.)
それらは知っているけれど,曖昧に使っているので,良くわからん,となっている人や,操作はわかるが,複数人での開発スタイルがわからない人を対象にしている.
gitの仕組みを簡単に理解することで,普段使うコマンドで出てくる単語の意味や,また自分の操作がどういう影響を与えるのかがわかるようになることを目指す.
所属する研究室では,これまでsvnを主なバージョン管理システムとして採用していた.
したがって,svnを意識した構成になっている.
の2章を参照のこと.
公式ドキュメントはこれ.
また,公式が出している書籍「ProGit」は良書だったのでおすすめ.
これには,web版(日本語)も存在する.
以下のような構成のディレクトリを考える.
2つのファイルがルートに,1つファイルがフォルダに入っている.
Repository
│ file1.txt
│ README.md
│
└─folder
file2.txt
3ファイルを加えるcommit (ddf39) | |
README.mdを修正してcommit (f4f2c) |
という操作をした場合の,gitのDBの実体は下図のようになる.
(全てのobjectへのkeyは自身のハッシュのとなる.)
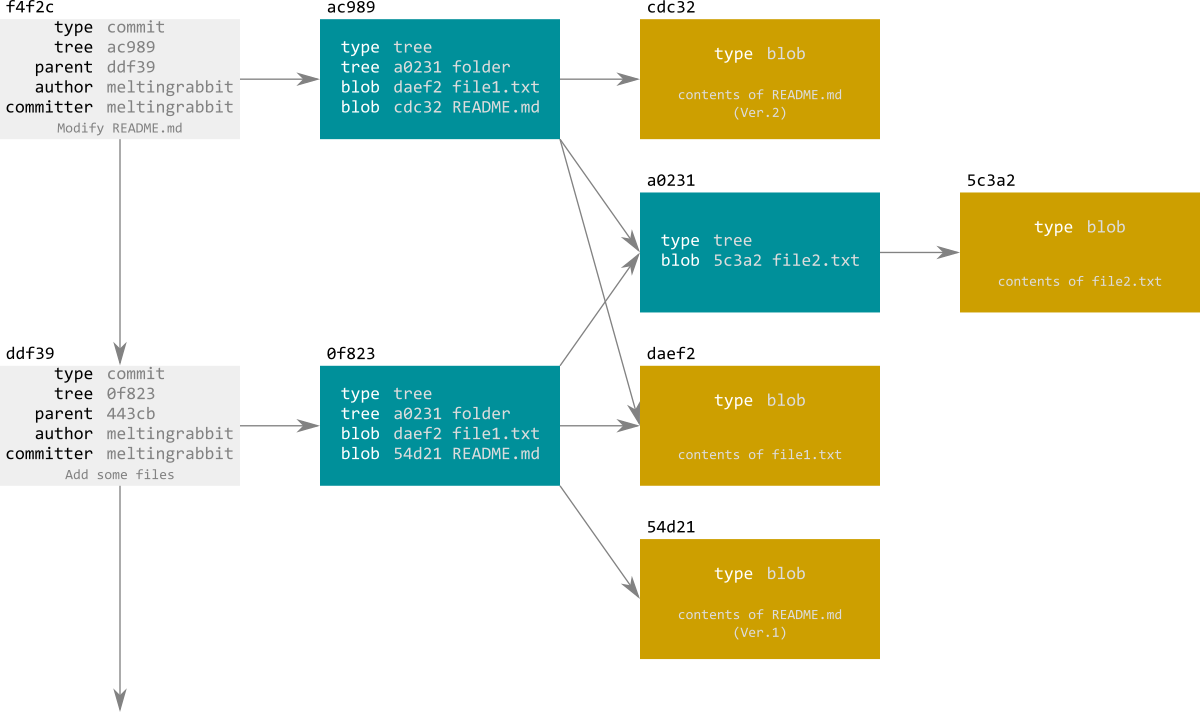
新しくcommitされたファイル(新規も修正も)は,(ヘッダーがつけられた後に)ハッシュ (SHA-1,正確には40桁.git上では,objectが一意に決まる長さまで指定してあげれば良い.) が計算され,圧縮されてblob objectとなる.
それらはtree objectによってリスト化され,tree objectもハッシュが計算される.
各commitは,
| スナップショットのrootを表わすtree objectのハッシュ | |
| 親となるcommit(これはmerge時などに複数になることもある)のハッシュ | |
| author, committer情報 | |
| commitメッセージ |
を格納し,自身のハッシュが計算される(つまり以後の変更が不能).
(ここらへんは,git cat-fileコマンドで遊ぶと楽しい.)
したがって,commitとは,それぞれがリポジトリ管理対象ファイルの "スナップショット" へのハッシュ(ポインタ)を持ったobjectであり,それぞれのcommitは親commitへのハッシュを持つ片方向リストである.
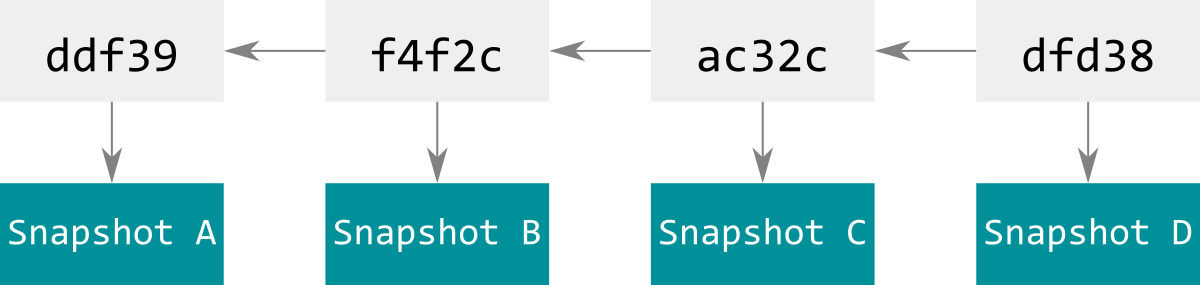
これは,特定のcommitを書き換える(例えば強制pushなどで)と,そのcommit自体のハッシュが変わってしまい,それを参照している子commitとの整合性が崩壊することを意味している.
(正確には,ハッシュが変わる=別のcommitになる,ので,過去の歴史がそこから分裂してしまうことになる.)
また,全てのcommitが差分データではなく,スナップショットを保持していることも,svnとの大きな違いである.
(スナップショットではあるが,DBの実体は図「」で示したとおり,更新されなかった(=ハッシュが変わらなかった)ファイルを重複して持つことはない.)
svnのリモートリポジトリのDB構成も簡単に見ておく.
db/revpropsに,commitメッセージやauthor情報がcommit毎に格納され,db/revsにそのcommitで変更されたファイルが圧縮され,1つにまとめられ格納される.
svnは,単一のリモートリポジトリサーバーのみにDBがあり,commit毎にリビジョンがインクリメントされていく(分散型のgitでは不可能).
そのため,db/revprops/2にはrev.2のcommitメッセージ等の情報,db/revs/2にはそのcommitで更新されたファイル実体が格納されることになる.
svnは単一ファイル毎のバージョニングを,リポジトリ全体で統一的にリビジョン番号を振っているイメージであり,各commitは差分であり,またハッシュが計算されることもない.
(svnでハッシュ (SHA-1) が使われるのは,working directoryにcheckoutされたファイルの初期状態を表すpristineくらいで,これはファイルの内容ではなく絶対パスのハッシュだったはず.)
Remote_Repository ├─conf ├─db │ ├─revprops │ │ └─0 │ │ 0 │ │ 1 │ │ 2 │ ├─revs │ │ └─0 │ │ 0 │ │ 1 │ │ 2 │ ├─transactions │ └─txn-protorevs ├─hooks └─locks
branchやtagの実体はref(参照)である.
これが,svnとの最大の違いである(svnではディレクトリ構造+プロパティ情報).
branchやtag(正確には軽量tag)はcommitのハッシュを持つ,つまり特定のcommitを指すrefである.
(正確には,tagはcommit以外のobjectを指すこともできる.)
branchはcommitとともに移動していくが,tagは移動不能である.
また,HEADとは,現在のwroking directoryにcheckoutされているbranchを指すrefである.
(なお,ハッシュを指定して特定commitをcheckoutした場合は,そのcommitを直接指すrefとなる.)
逆に言うと,checkoutとは,wroking directoryに展開されているbranchを切り替え,HEADを移す作業である.
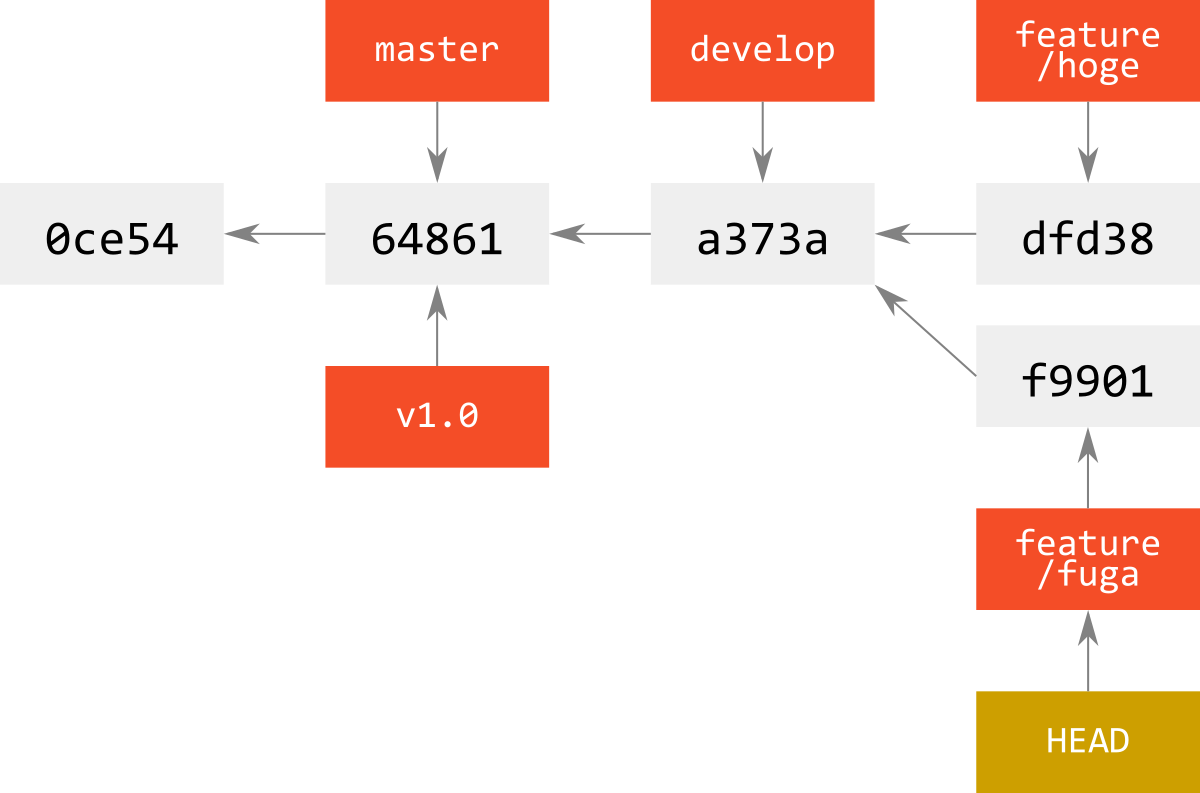
つまり,新しくcommitすると,HEADが指していたcommitが親となるcommitが形成され,その新しいcommitにbranchが移る(branchを指しているHEADもbranch移動とともに動く).
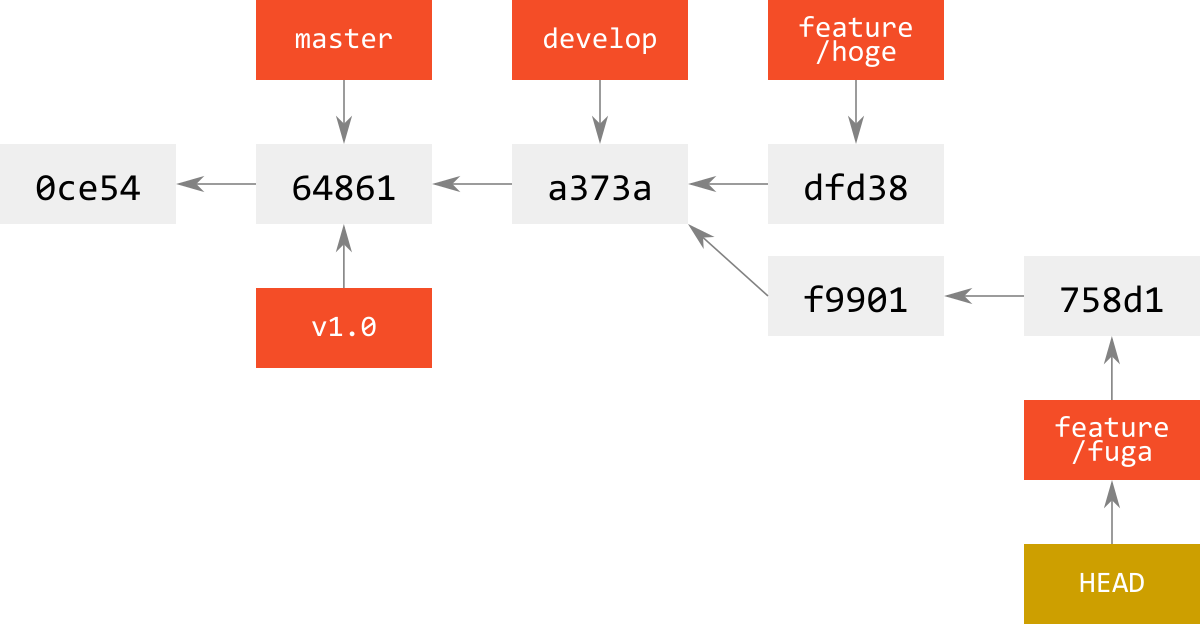
svnは,branchを切った瞬間に,commitが走る(=リビジョン番号が上がる).
つまり,branchを切るということは,切る元のbranchのスナップショットをまるっと新しいbranchとなる別ディレクトリにコピーし(※ 無駄なので,実体は複製されてはいない),リポジトリ全体のディレクトリ構成とファイル配置,プロパティが変更され,その変更差分をcommitとして刻むことを意味する.
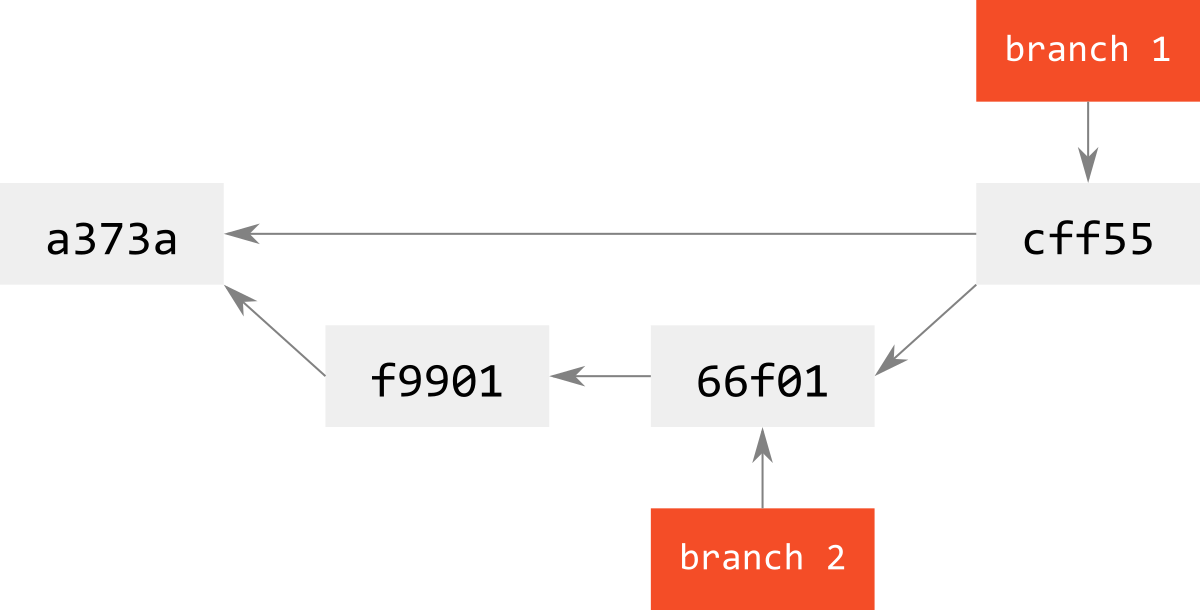
svn利用者は,下図のようなログを見ると,「なんでdevelopとmasterが同じところを指しているのか??」と訳が解らなくなる.

実体は次の図のようになっていて,branchはただのrefなので,それは同じところを指してもおかしくない.
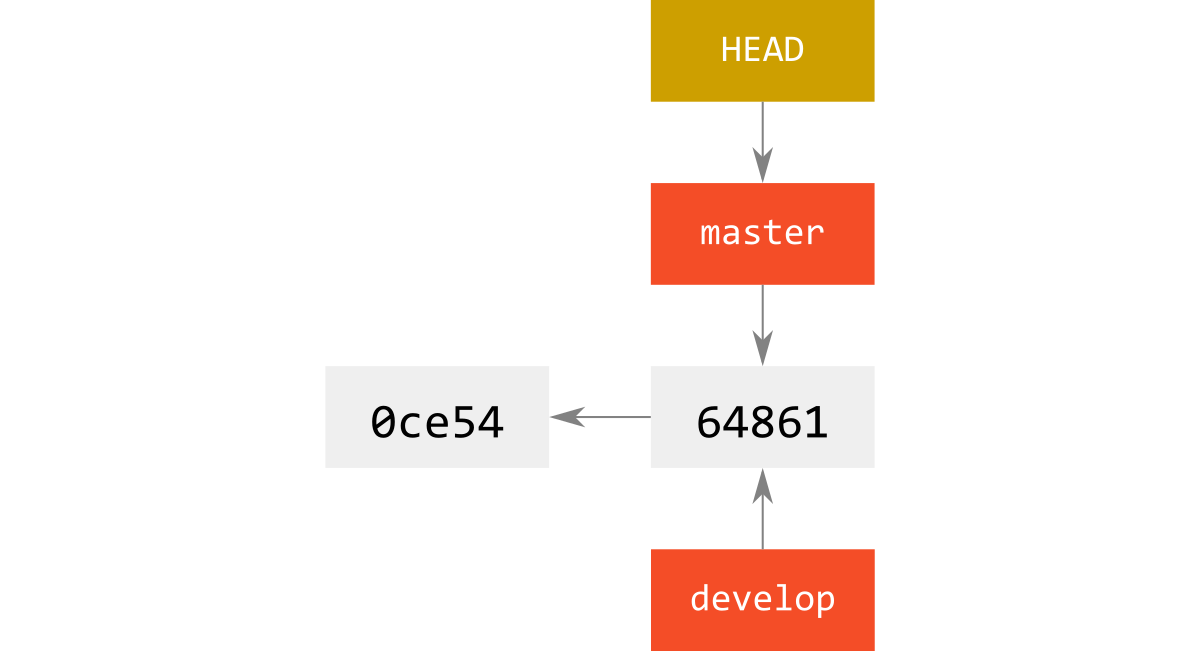
ここで,developにcheckoutして,2回commitすると下図のようになる.
これでもまだ,svnでは起きている分岐が発生していないことに注目したい.
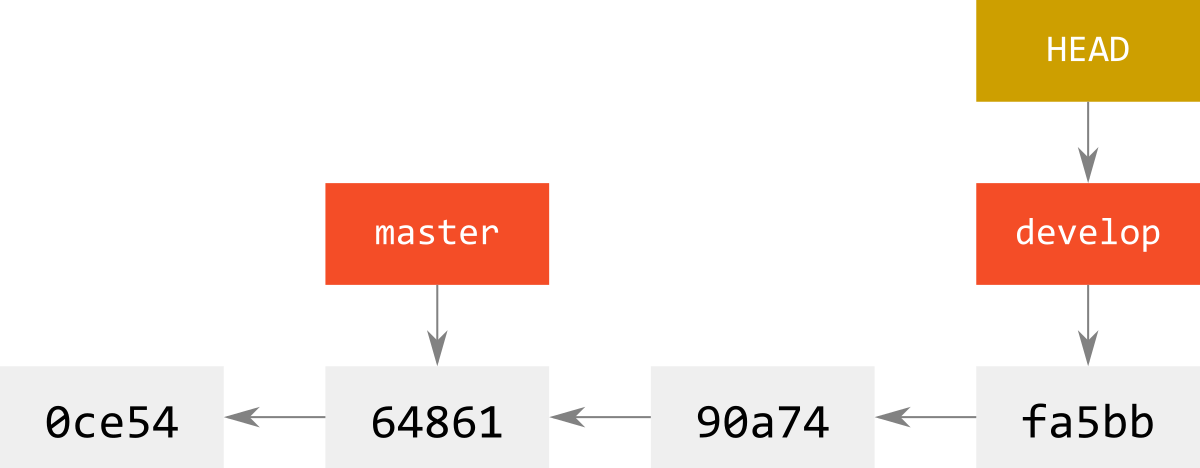
masterに対して,別のcommitや他のbranchからのmergeがあってはじめて,下図のように分岐が発生する.
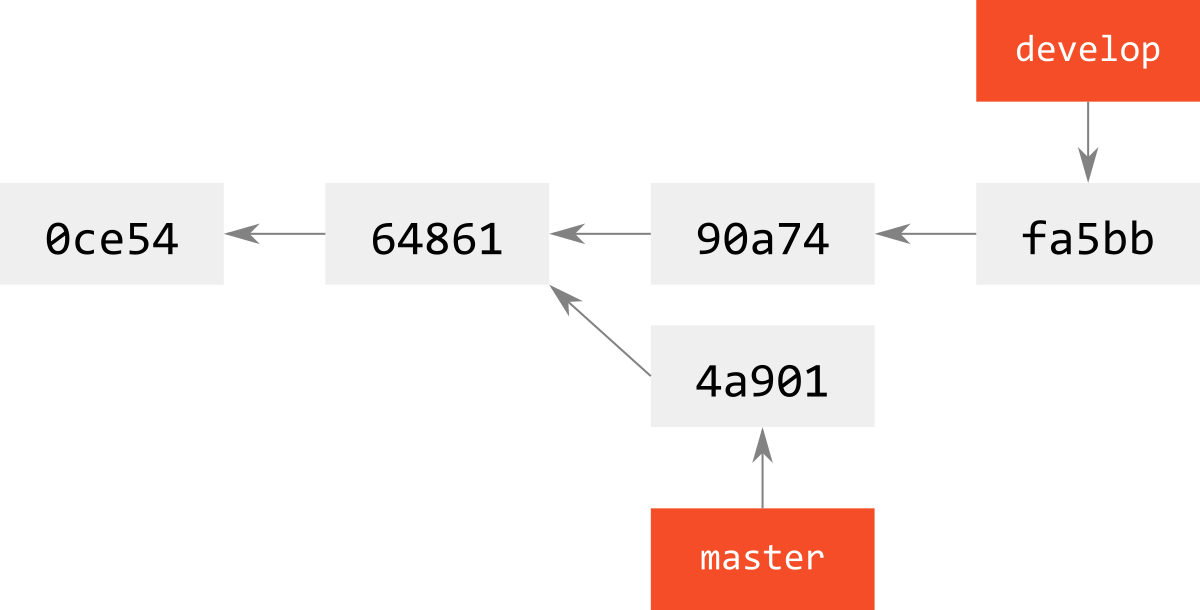
この概念は,mergeなどで重要になってくる.
あるbranchの作業を別のbranchに取り込む作業である.
ここでは,svnでは原理上あり得なかった,fast-forward mergeについてまとめる.
なお,rebase mergeやsquash mergeなどの高度なmergeもあるが,commitとほぼ同時にpushしているような研究室の環境では,これらは「」で述べるような問題を生むことがあるので,研究室のリポジトリでは使う機会はほぼなく,割愛する.
(詳細は「」で述べるが,pushする前のローカルリポジトリで歴史をきれいに整理するのに使うのはOK.)
下図のように,branch 1にbranch 2からmergeすることを考える.
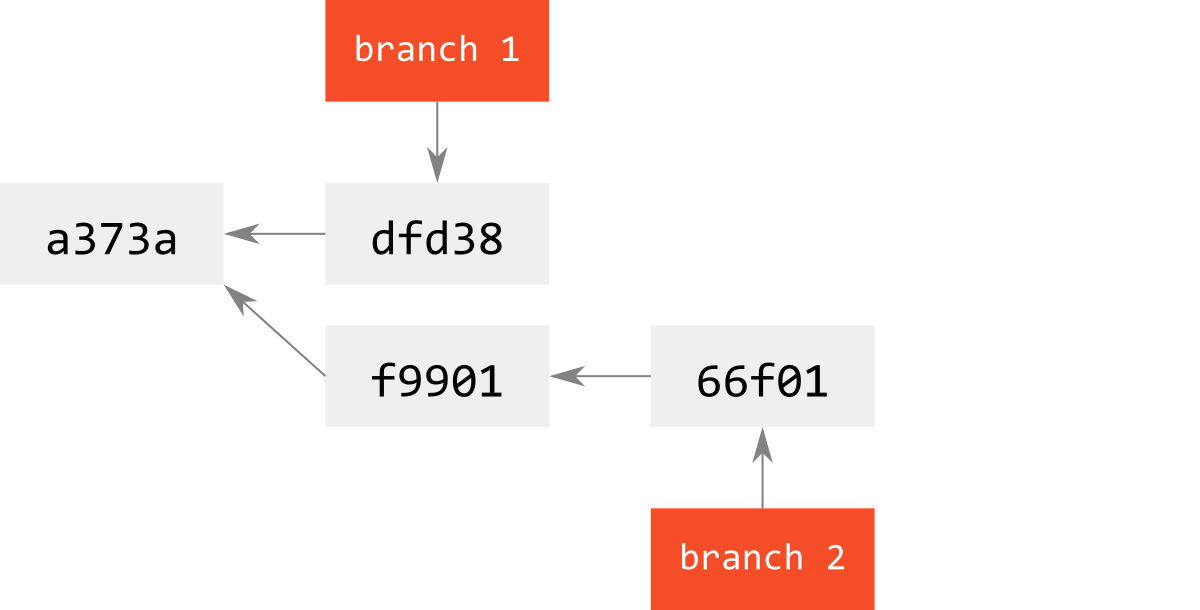
merge後は,普通に下図のようになる.
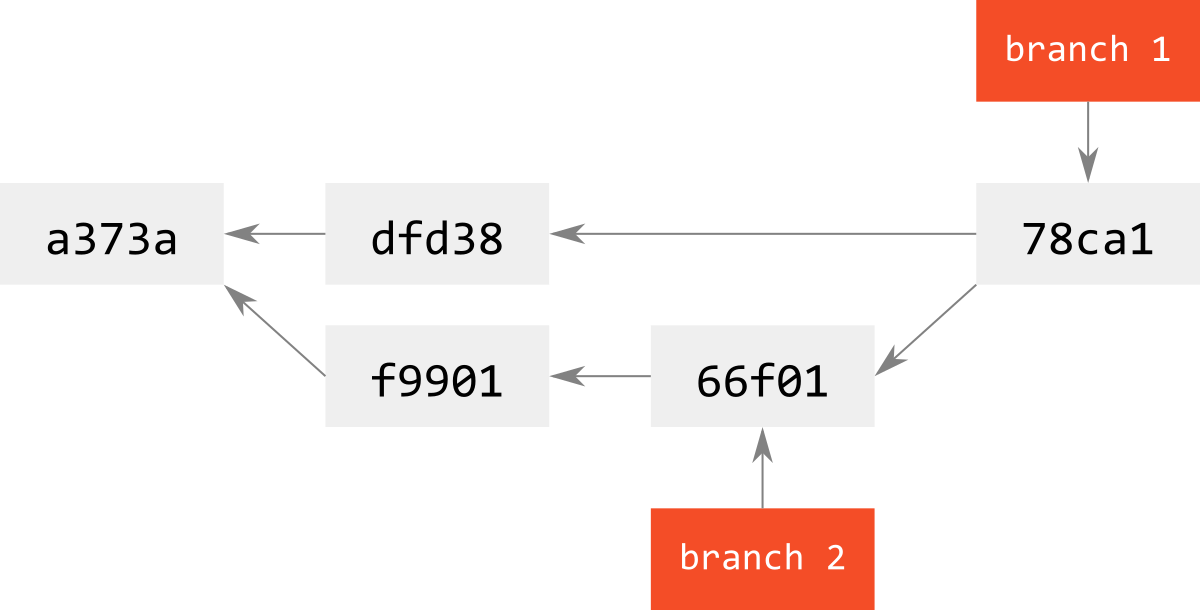
では,次のようにbranch 1がbranch 2の直系の親である場合を考える.
これをmergeすると,デフォルトでは下図のようになる.
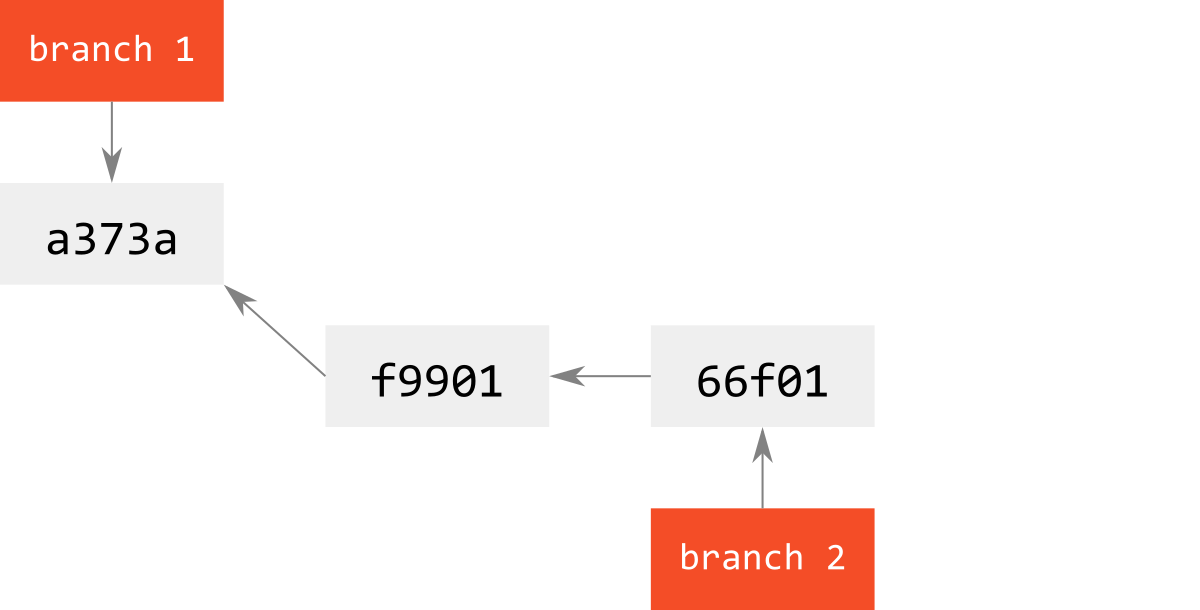
このような,commitが発生しない,単なるrefの移動のみのmergeをfast-forwardと呼ぶ.
例えば,branchを切ったものの,長いことなにもせずに気づいたら元branchの更新が進んでいた,といった状況では,svnの場合は一旦そのbranchを消してから切り直すことになるだろう.
一方で,gitではこのfast-forward mergeによって,branchを切り直した状況と等価にすることができる.
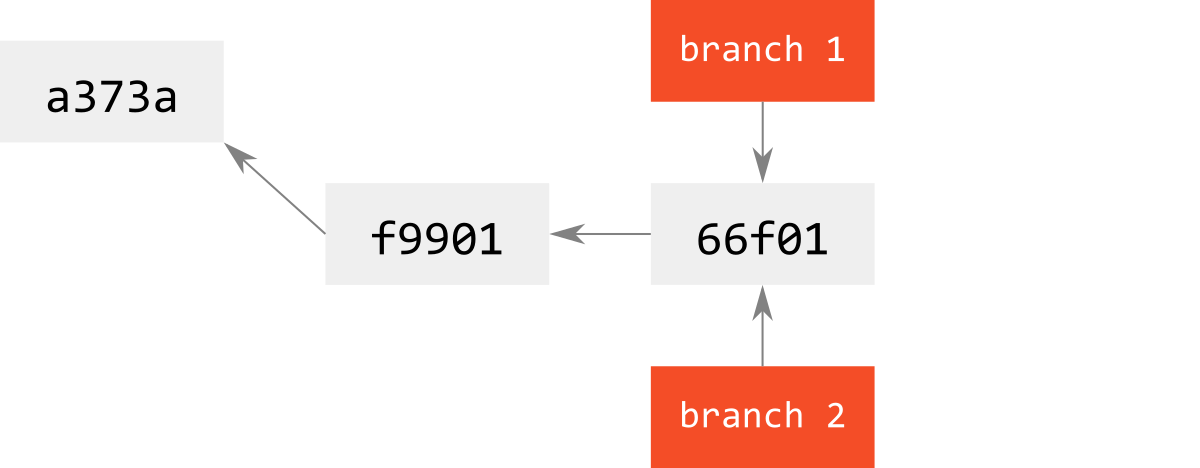
fast-forward状況化でも,--no-ffオプションを付けることによって,下図のようにcommitを打つmergeができる.
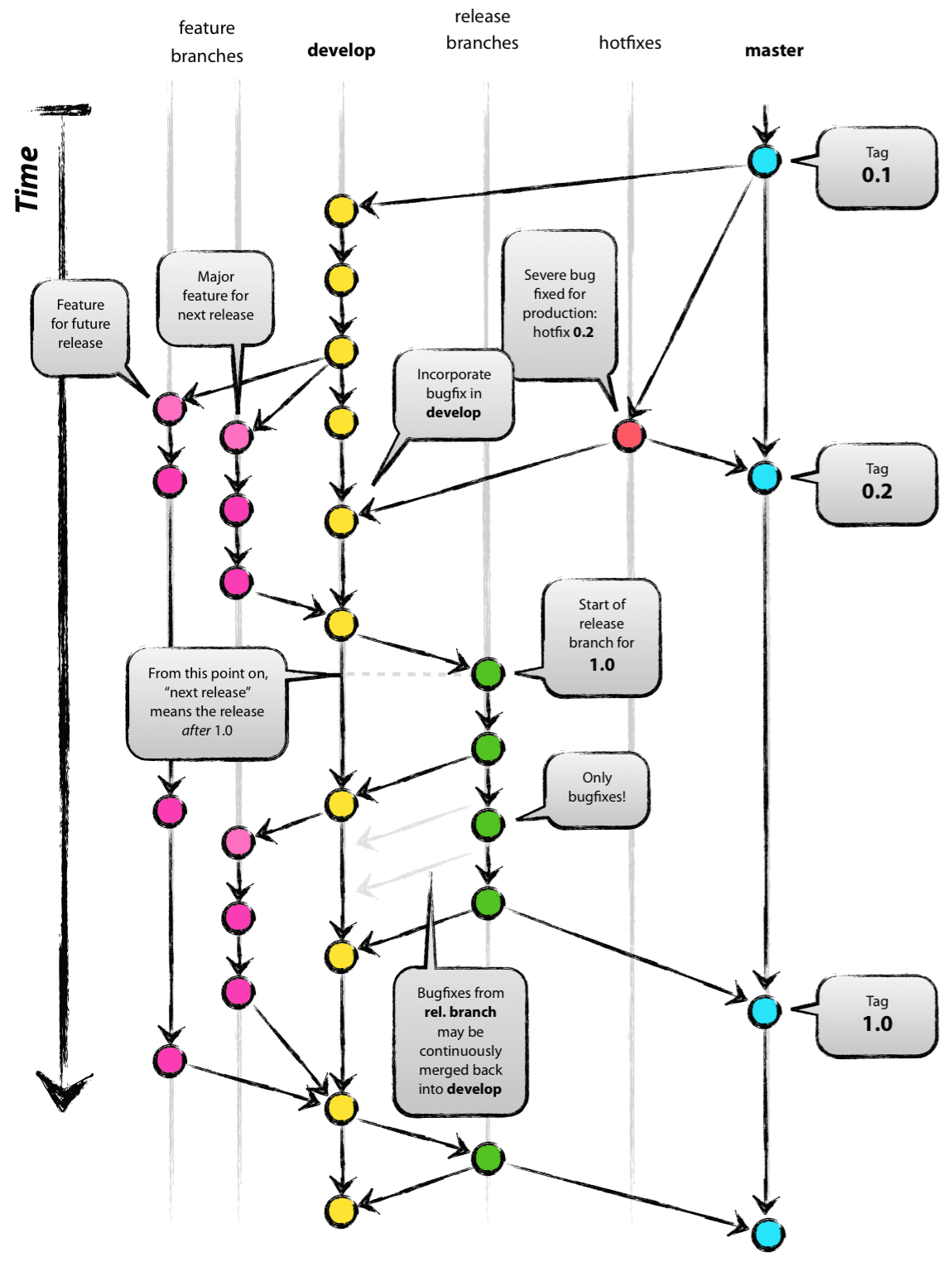
明示的にbranchを切ったことが残るので,「」でも述べるが,研究室リポジトリではfeature/*からdevelopはこれを推奨する.
(研究室の衛星OBCの搭載ソフトのGitLabリポジトリのmerge requestでは,デフォルトで--no-ffになるように設定されている.)
このあたりのmergeオプションを下表にまとめておく.
| mergeオプション | fast-forward状況下である | fast-forward状況下でない |
--ff(デフォルト) | fast-forward | merge commitを打つ |
--no-ff | merge commitを打つ | merge commitを打つ |
--ff-only | fast-forward | 失敗(拒否) |
単一のリモートリポジトリから特定のスナップショットをcheckoutして作業するsvnと異なり,gitは分散システムである.
したがって,リモートリポジトリとローカルリポジトリの構成は全く同じであり,リモートリポジトリが複数あっても構わないし,AさんがBさんのローカルリポジトリに対してpush / fetchしたりする(つまり,Bさんのローカルリポジトリをリモートリポジトリとみなす)ことも可能である.
最近では,単一のリモートリポジトリを用いて,それに対して各々がpush / fetchするという,システムとしては分散であるが,運用としては中央集権的な利用をすることが多い.
originをリモートリポジトリのことを指す,と思っている人も多いが,たまたまgitのリモートリポジトリ名のデフォルト値がoriginなだけであって,好きな名前をつけることができる(というか,複数のリモートリポジトリを使うなら,origin以外もつけないと衝突する).
(蛇足だが,master,というのも,gitのデフォルトbranch名がmasterなだけで,別のbranchをデフォルトbranchに設定することも可能である.)
さて,push / fetchの話をするには,今までローカルリポジトリのみを考えてきたが,ここからはリモートリポジトリについても考えなくていはいけないことに注意する.
まずfetchについて.
fetchとは,リモートリポジトリにある全てのrefから到達可能なobjectのうち,ローカルリポジトリにないものを取得し,さらにローカルリポジトリにあるリモートリポジトリのrefをリモートリポジトリにあわせて更新する "操作" である.
(「fetchとはリモートリポジトリの内容をローカルリポジトリに持ってくるだけ」とか適当な解説だけだと,以下の例などの現象を理解できないと思っている.)
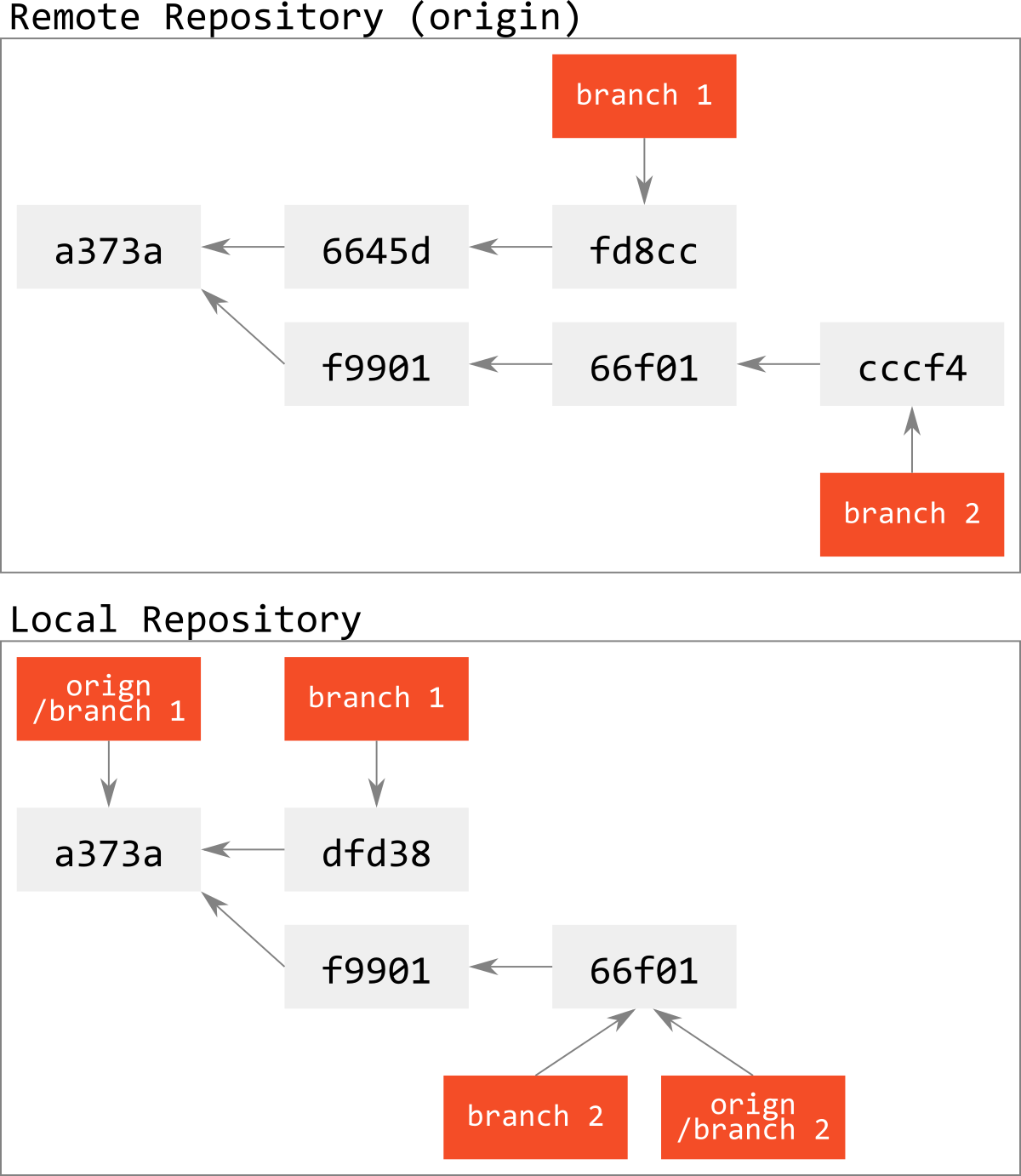
例えば,図で表すとこんな感じ.
objectを取ってくるだけなので,リモートリポジトリでbranch 1が進んでいたりしても,コンフリクトなどは本質的に起こりようもない.
(なお,origin/*はfetchの時のみに更新される=前回のfetch時のリモートリポジトリのrefの位置を表している.)
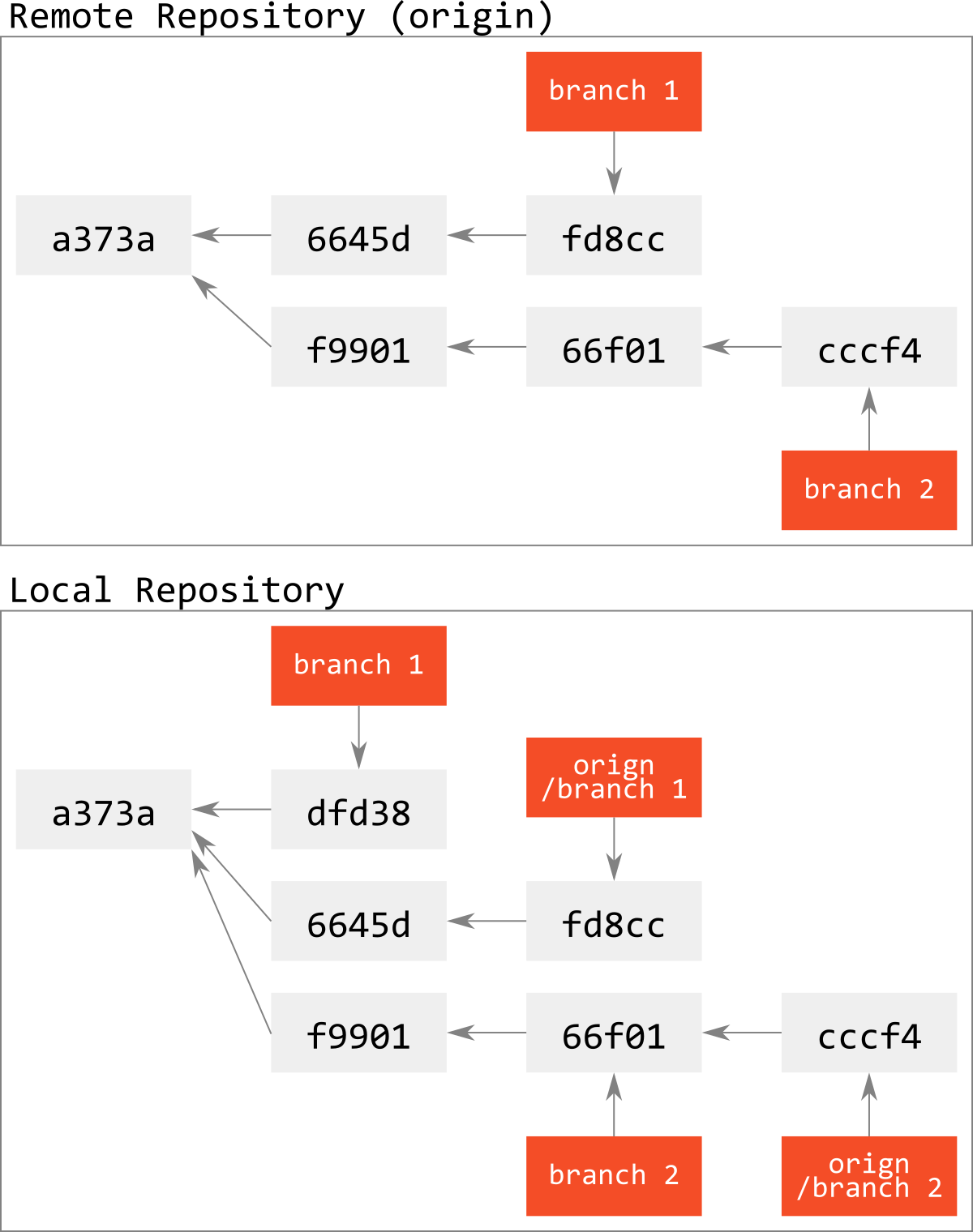
「え? なんでbranch 1でエラー起きないの? fetch前で,リモートのbranch 1はローカルとは違う更新かかってるじゃん?」と思った人は,commitはobjectの片方向リストであり,branchはrefであることを思い出そう.
普通にgitを使っていれば,ローカルリポジトリではbranch 1とorigin/branch 1は関連付けられている(詳細は "リモート追跡branch" で調べて)ので,branch 1の更新をpushしたい場合には,この2つをmergeする必要がある.
pullとは,fetchしたあとに,ローカルのHEADが指しているbranchにmergeする操作である.
mergeが発生するので,コンフリクトなどが起きうる.
なので,個人的には,pullは使わず,fetchしてmerge(やら場合によってはrebaseやら)したほうが何やってるかわかりやすく,変なことにもなりやすい,と思っている.
pushとは,現在リモートリポジトリのDBにはない,push対象となるローカルリポジトリのbranchから参照されるobjectをそのDBに追加し,さらにリモートリポジトリの対象branchの参照先を移動する "操作" である.
fetchの逆みたいなもの.(といっても対称ではないが.)
注意点としては,リモートリポジトリ側でmergeしてくれる人はいないので,リモートのbranchとの関係が,fast-forward状態になっていないと失敗する.
つまり,リモートリポジトリ側で更新があった場合は,fetchしてmerge(やら場合によってはrebaseやら)しておく必要がある.
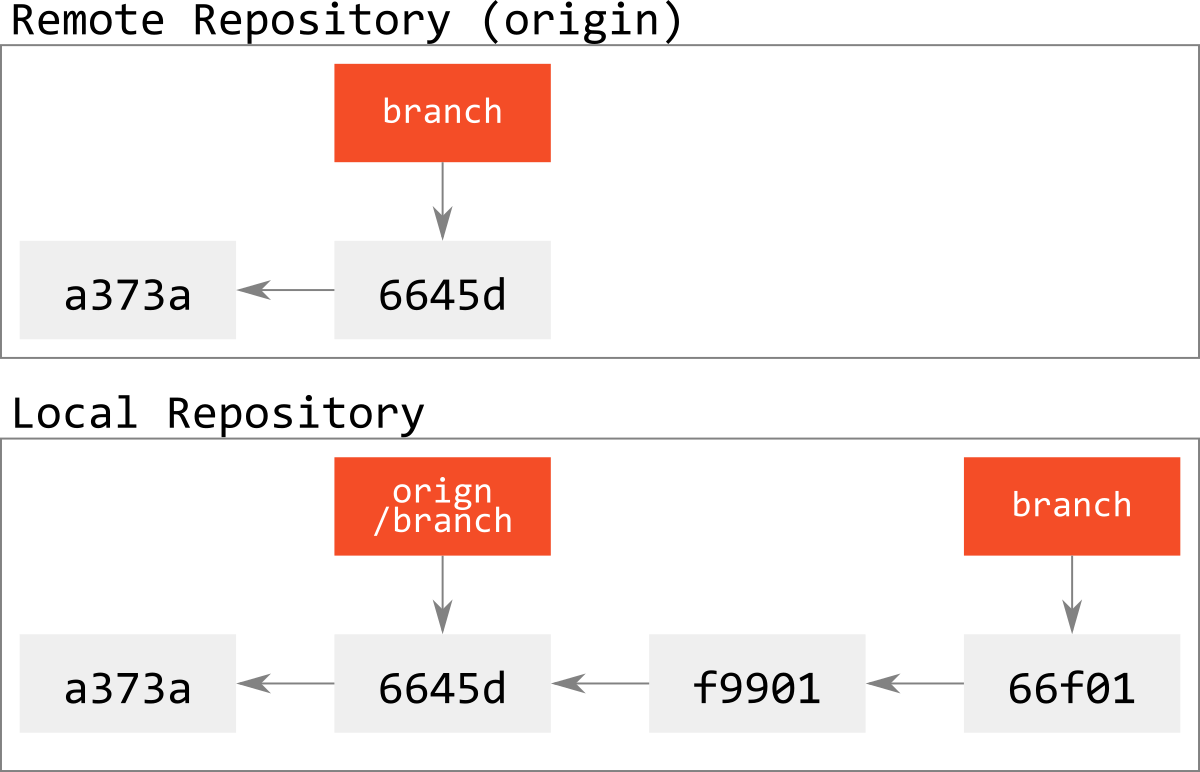
図で表すとこうなる.
fast-forward状態であること仮定する.
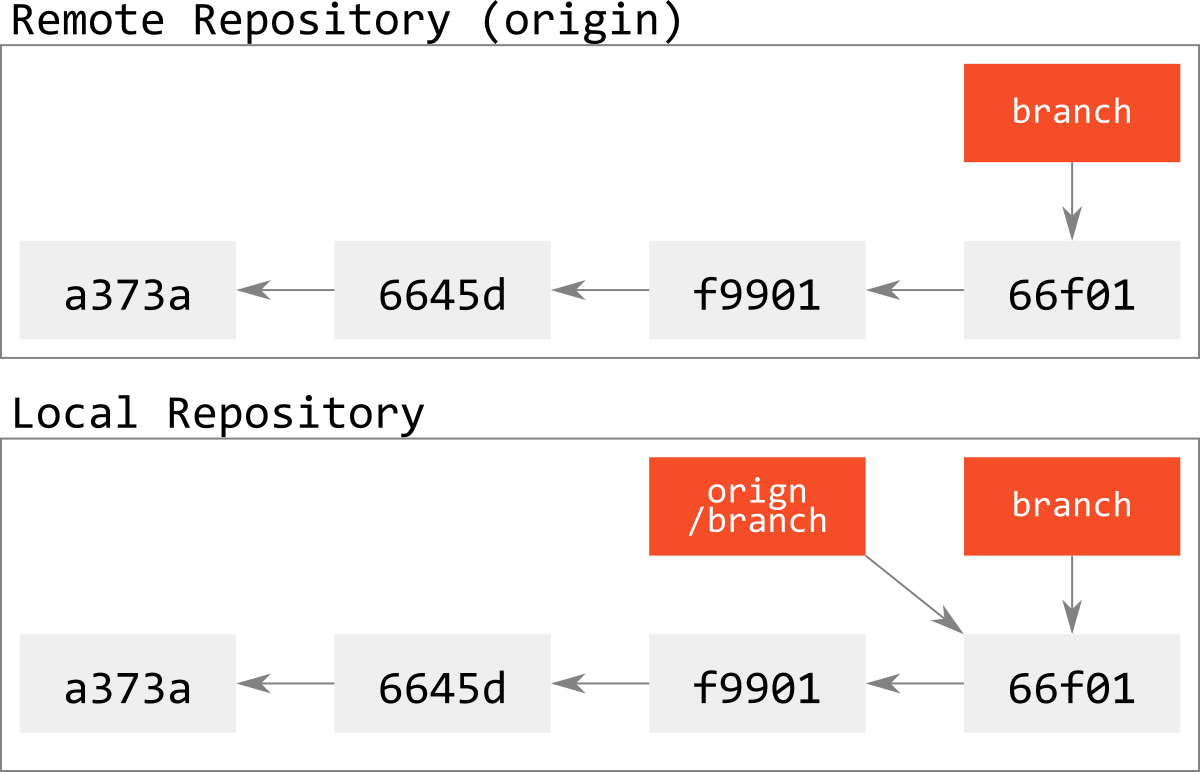
fast-forward状態でないのに,強制pushすると次のようになる.
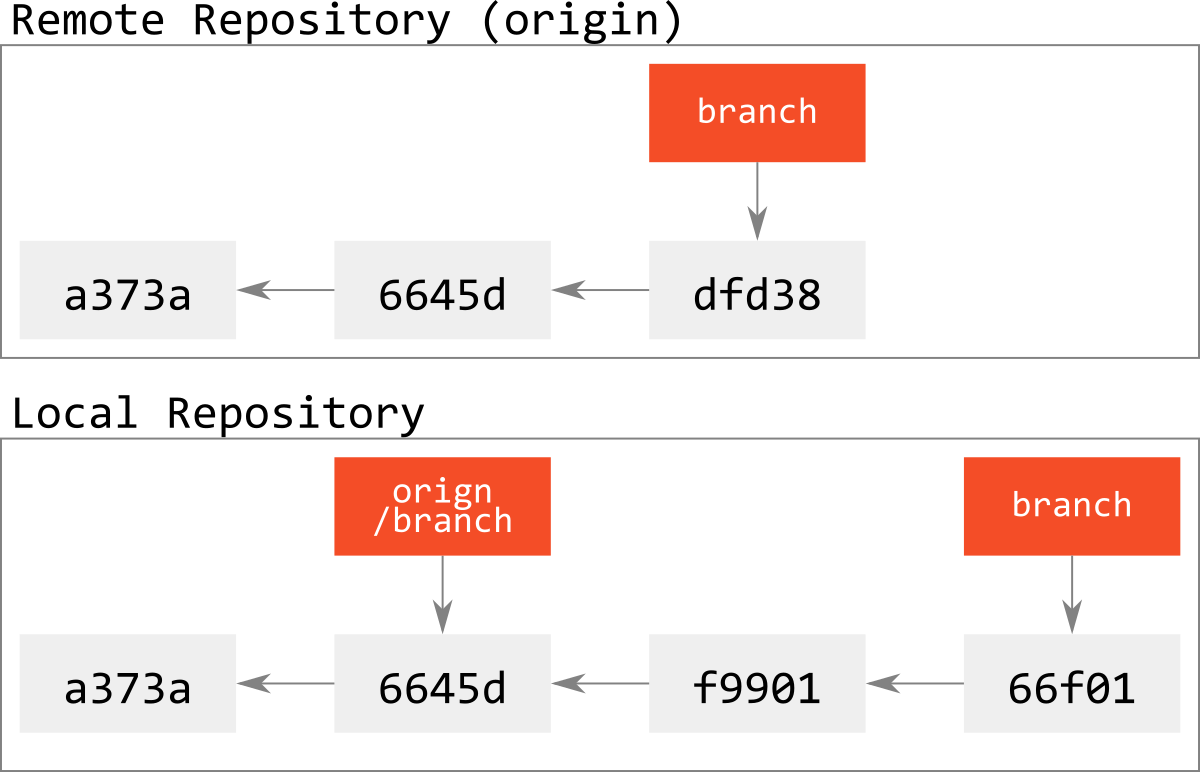
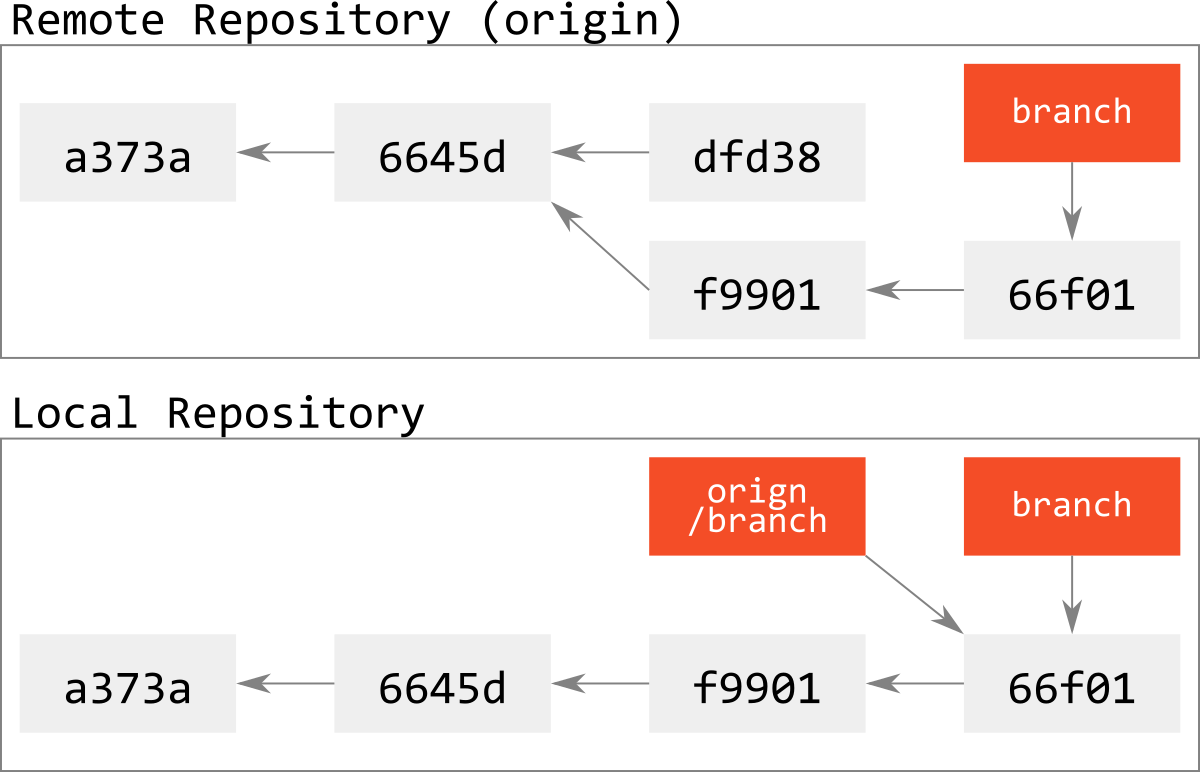
リモートのcommit dfd38に到達できるrefが失われるので,このbranchが事実上失われることになる(svnではbranchが消失することはない).
また,このbranchからcommitを打った別開発者がpushしようとするときに,またDB不整合が生じてしまう.
このようなbranchの消失については,「」で詳しく述べる.
もちろん,多少の変更点(カスタマイズ)はある.
安定動作版.
このソースコードを実機に書き込んだり,また検証用シミュレータに取り込んでも問題が起こらないとされているバージョン.
適当なタイミングでdevelopから責任者がmergeする.
基本的にはtagでバージョンを付ける.
masterからどこか別のbranchへmergeすることはないはず.
push禁止.
feature/*で実装され,検証が終わったらdevelopにmergeされる.
したがって,おそらく問題ないと思われているコードの最新版が集積される.
feature/*での開発を一旦ここでまとめて,落ち着いたらmasterまでmergeする.
もちろんpush禁止.
機能開発branch.
developから切られ,developにmergeされる.
feature/*→developへのmergeは,所定のテンプレートにそったmerge request (pull request) を発行することで行う.
merge requestをMaintainerが確認し,テストコードを走らせ,フォーマットやコード規約等を確認し,問題がなければmergeする.
以下が大切.
| merge requestやissueはテンプレートが複数登録できるので,登録してフォーマットが統一されるようにすること. | |
| 後でわかりやすいように,issueと関連付けを行うこと. | |
| 適切にlabelをつけ,フィルタできるようにすること. |
前回のプロジェクトでは適当にmergeしていたため
| 管理しきれない,よろしくないコードが溢れた | |
| コーディングしたその人しか内容を把握していないコードがあり,試験での不具合発生時などに困った | |
| 後々になってコードレビューをするなど,二度手間になっている |
といったことが散見されたので,今後はmerge request制度を徹底し,コーディングした人以外のチェックのもとでmergeする.
なお,ここでのmergeは--no-ffで行う.
次のことも大切.
| 1つのbranchを大きくしすぎないこと. | |
| わかりやすいbranch名をつけること. |
develop→masterのmergeが大変なときに使う一時的なbranch.
masterへのmerge時にdevelopの更新を止めないようにするためにつくる.
今回は必要なことはほぼないはず.
試験用branch.
developから切られる.
大きな環境試験など,試験中に修正が入る可能性がある場合に切る.
試験が終了したらtagを切り,必要があればmasterへmergeする.
branch内で変更があれば,developにもmergeして変更を取り込む.
ここでのmergeも--no-ffで行う.
早急にmasterを変更したい場合に作る,非常用branch.
こちらも,masterだけでなく,developにもmergeして変更を取り込む.
ここでのmergeも--no-ffで行う.
なにかしたいと思ったら,ggればたいてい出てくる.
ここでは,教育的な(?)ことだけまとめた.
fetch(ないしはclone)によって,リモートリポジトリの,refから到達可能な全てのobjectがローカルに落ちてくる.
これは,現在のrefから辿れる過去のcommitで登場した全てのファイルが完全な形でローカルに降ってくる,ということを意味している.
svnでは,(キャッシュを除いて)ローカルにあるのはそれぞれのファイルの最新版のみである.
このような仕組みであるので,適当にバカでかいバイナリをpushしてしまった場合,仮にそれを打ち消すpushをしたとしても,そのファイルのサイズ(実際はblob object生成時にzlibで圧縮される)を,そのリポジトリをcloneする全ての人のPCのディスク容量に対して消費することになる.
また,CADデータやメディアデータなどのバイナリファイルをgit管理すると,リポジトリがまたたく間に肥大化することが想像できる.
(svnのように,サブディレクトリ単位でcheckoutしてcommitしたりできないし.)
そのような事情もあって,gitではバイナリファイルなどのミスpushを避けるべきであるし,大きなバイナリを頻繁に更新するようなものをバージョン管理する(かつ開発者が少数)ならsvnの方がいいのでは? と思ったりする.
(学会論文等のリポジトリも,いじるのはほぼ1人でコンフリクトの恐れも少ないなどといった様々な要因から個人的にはsvnで管理するのが好き.)
補足だが,一応gitにもLFSという,大きなバイナリを外部ファイルサーバーに配置し,管理情報のみgit管理する,という仕組みもあったりする.
svnだと,プロジェクトで1つのでかいリポジトリをどーんとつくって,その中で細分化しても問題なかった.
先述の理由より,gitだと取り回しが悪すぎるので,なるべくリポジトリは細かく切ること.
例えば,補助ツールみたいなのがあれば,別リポジトリをたてる.
git configは3箇所にある.
1つめはsystemレベルで,C:\ProgramData\Git or C:\Program Files\Git\mingw64\etcに.
2つめはglobalレベルで,C:\Users\${username}に.
3つめはlocalレベルで,リポジトリ内の.\gitに.
gitの設定は,この順番に適用されていき,同じ設定は上書きされていくので,包括的な設定は上位に,そのリポジトリ固有の設定はlocalに記述する.
なお,git config -lでその環境で適用される設定の一覧が確認できる.
gitリポジトリマネージャーは,そのアカウントとcommit上のauthorをuser.emailで紐付けている.
このメールアドレスは公開されてしまうので,GitLabやGitHubでは,5730660-meltingrabbit@users.noreply.gitlab.comといった公開されてもいいようなユーザーアドレスを発行できるので,これを登録しておくとよい.
commit時に無視されるファイル.
一時ファイルなどのcommitすべきでないファイルを登録しておくことで,他人に迷惑をかけるのを防ぐ.
書き方は適当にggって.
merge前やcheckout前などに,現在のworking directoryの変更差分を一時的に退避させる機能.
退避に名前をつけることや,複数個を退避させることもできる.
また,退避元branchと退避からの復元先branchは異なっても良い.
何かといろいろ使えるので便利.
詳細はggって.
通常のgrepも(というか,grepやらsedやらawkやらは)めちゃくちゃ便利なので,使えばいいと思う.
(というか,こういうの使わないと,諸々をテキストファイル化するメリットを享受できないのでは? と思ったり)
しかし,git grepは通常のgrepにはない機能として,commit済みの全objectが検索対象なので,すごい.
様々な操作をトリガーに,特定のスクリプトを走らせることができる.
commitメッセージが規約通りでなかったら,commitを中断させる,とか,push前にフォーマッタを走らせるとか.
衛星OBCの搭載ソフトのリポジトリには,各ユーザーのローカルリポジトリにpre-cimmit hookが自動展開されるギミックを追加してある.
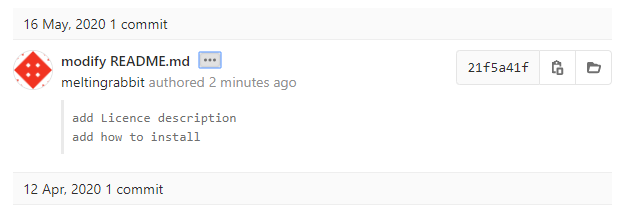
commitメッセージは
modify README.md add Licence description add how to install
のように,2行目を空白行にすることが推奨されている.
また,1行目は <動詞の現在形> + <目的語> というフォーマットが浸透している(気がする.)
(1行目が簡潔に書けないようなら,commitを分割するべき)
こうすると,GitLabやGitHubなどのサービスや適当なGUI Gitツールでは,下図のように詳細を表示したり隠したりできるので,3行目以降に詳細を書くことが推奨されている.
歴史の修正とは,commitハッシュの変更の伴う全ての操作のことである.
commitとは,ハッシュ列の片方向リストである,というのは何度も述べた.
公開リポジトリにプッシュしたコミットをリベースしてはいけない
この指針に従っている限り、すべてはうまく進みます。 もしこれを守らなければ、あなたは嫌われ者となり、友人や家族からも軽蔑されることになるでしょう。
pushしたcommit(commit A)に対して,もし他の人(Zさん)がそれに続くcommitをしていた場合に,その親となるcommit Aがrebaseやcommitのやり直しなどによって,別のcommit Bとして登録されてしまった場合,Zさんのpushによってcommit Aは復元されてしまい,同じようなcommitがAとBで2回歴史に刻まれるといったことになってしまう.
こういったDBの不整合はトラブルの元なので,避けなければならない.
基本方針として,未公開commitは好きに修正してよく,公開済みcommitの修正は厳禁である.
push前の,ローカルリポジトリにしかない一連のcommitの歴史は,好きに修正してよい.
rebaseによって,mergeでまざるcommitの順番を変えたり,複数のcommitをまとめたり,単一のcommitを複数に分割したり,と歴史をきれいにするのは悪くない.
一度pushしてしまったら,そのcommitのハッシュが変わるよな(=歴史が分岐してしまうような)作業は慎むべきである.
本当に必要な歴史修正(でかいバイナリを消すとか,コードの公開にあたって過去の特定のファイルを抹消するとか)は,他の全てのローカルリポジトリをpushし,他のすべての作業を停止した状態で行う必要がある.
個人的な意見として,
commitはローカルリポジトリでこまごまとやって,
push前にreset soft/mixedなどで戻して,まとめてcommitしてpush,などがきれいなのではないだろうか?
git commit --amendでやり直せる.
commitメッセージを書き直したい,とか,ファイルをaddするのを忘れた,とか.
(なお,これはgit reset --soft HEAD^してからgit commitと等価.個人的にはこっちを推したい.)
当たり前だが,commitのハッシュは変わるので,書き加えられる歴史は分岐している.
ミスcommitを取り消してpushすると,リモートリポジトリにはそのミスcommitはアップロードされない.
git reset --hard HEAD^などで前回のcommitを取り消した場合,下図のようになる.
(省略しているHEADは常にdevelopを指している.)
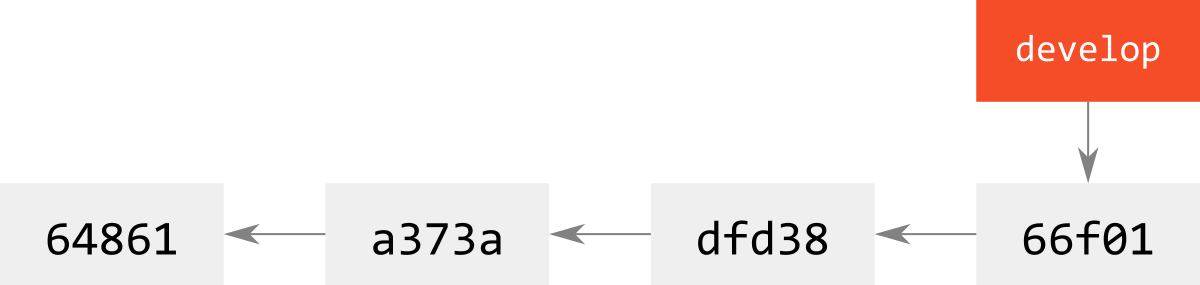
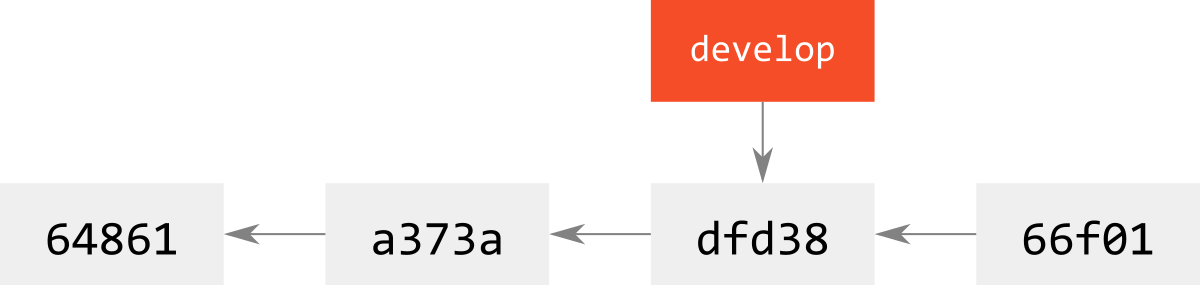
そして修正して新しいcommitを打つと,当然ハッシュは変わるので,別commitとして新たな歴史が刻まれる.

これをpushした場合,ミスcommit 66f01とそれからのみ参照されるobjectはリモートリポジトリにはアップロードされない(pushの定義から自明).
なお,66f01などはGC(ガベージコレクション)対象となるので,いつか削除されるが,それまでであればreflogなどから復元は可能.
今まで見てきたとおり,git commit --amendやreset soft/mixed/hard(これは,HEADとindexとworking directoryをどこまで戻すかを決めるオプション),rebaseなどで,commitを書き換えることは容易である.
(もちろん,今まで言ってきたとおり,容易であってもpushしたcommitの修正は厳禁.したいときは管理者言うこと.)
正確なイメージは,修正というよりもむしろ,ローカルリポジトリ内に様々な歴史分岐を作ることができて,最後にpushした歴史がリモートリポジトリに刻まれ,選ばれなかった歴史はそのうちGCでなかったことにされる,といった感じか.
したがって,commitはラフにやっていけばいいと思う(そのままpushしなければね).
そういう意味では,適切なresetができるように,resetコマンドで何ができるかを把握しておくのはおすすめ.
ProGitの「7.7 Git のさまざまなツール - リセットコマンド詳説」などが,わかりやすいかもしれない.
svnでは,branchを切ること,削除すること自体がcommitであった.
一方でgitではbranchはrefである.
そのため,リモートリポジトリのmergeされてないbranchを削除したり,強制pushでrefを上書きしたりすると,一連のcommitが復元不可能になる場合がある
以下のような状態を考えよう.
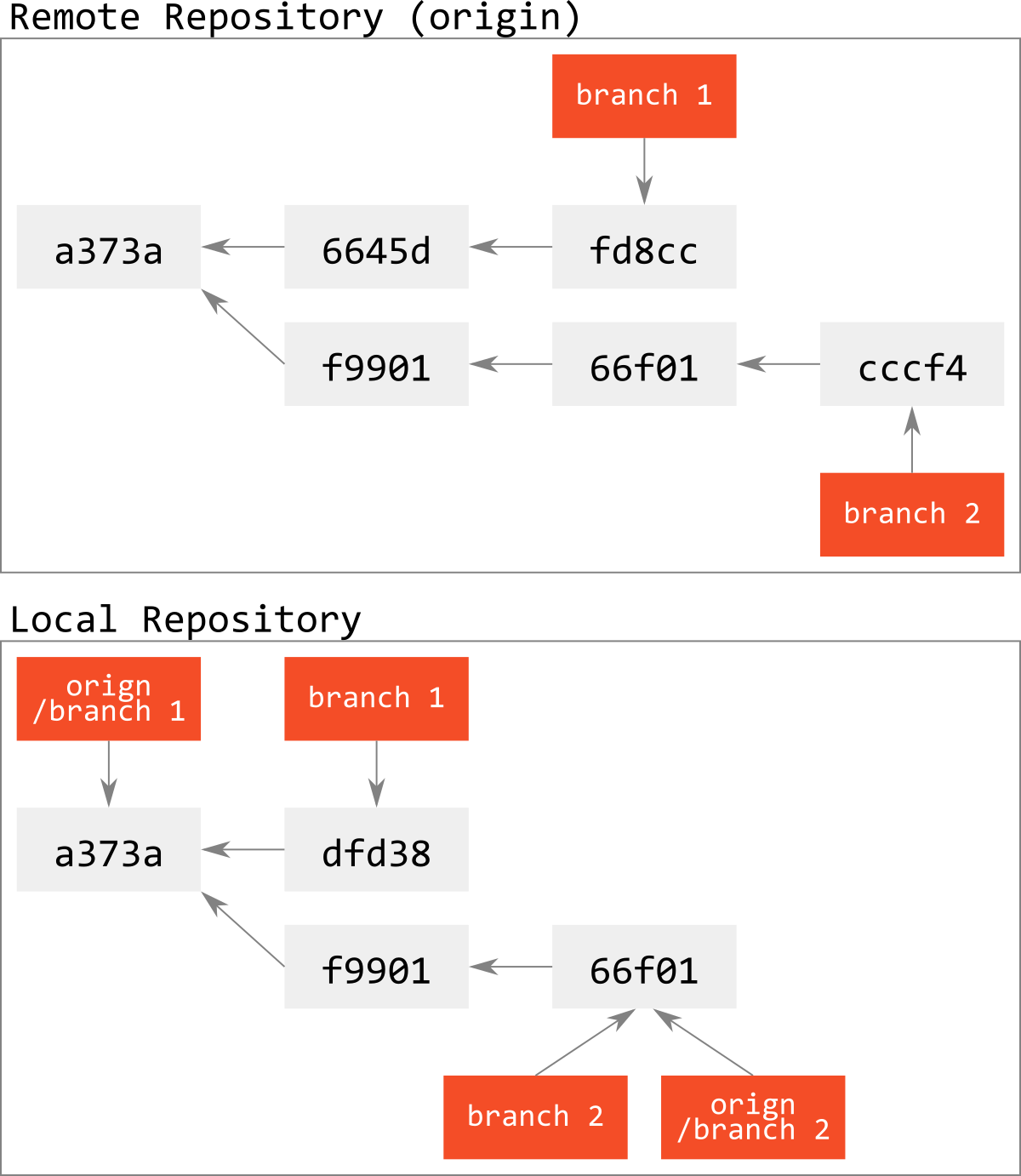
ここから,まだどこにもmergeされていないbranch 1をリモートリポジトリから削除しよう.
すると,下図のようにcommit object fd8ccはどこからも参照されない浮いたobjectとなり,fd8ccやその親の6645dは,いかなるrefからも到達不可能になる.
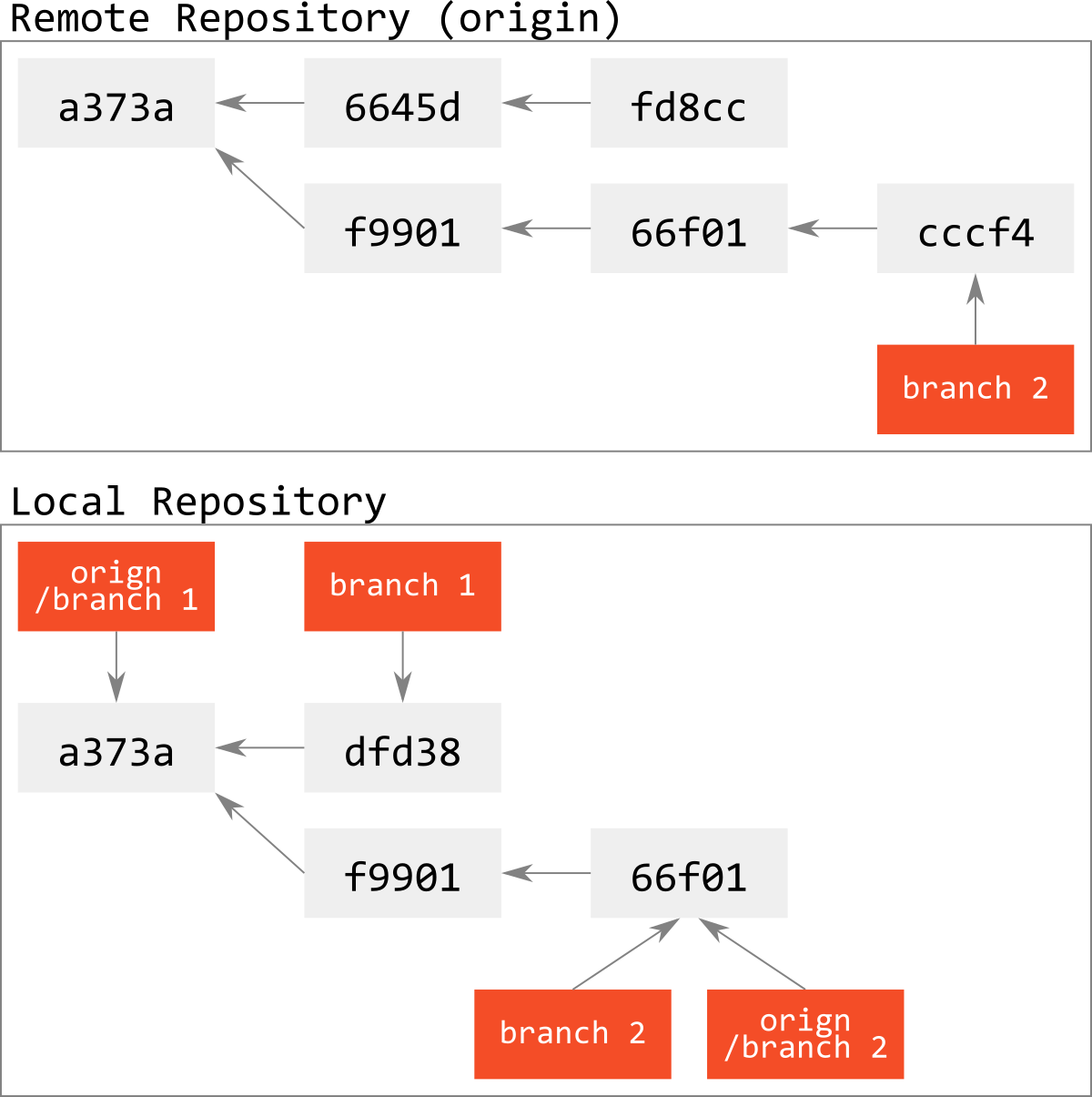
これを,いくらfetchしたとしても,このcommit objectとそれから参照されるtree, blob objectはローカルリポジトリに降ってこない.
つまり,このbranchは失われたことになる.
branchが復元不能になる,というのは,svnではあり得なかった話である.
こうなってしまったら,リモートリポジトリのサーバーにログインし,reflogをたどるか,git fsck --allとかいうplumbingコマンドを打って,どこからも参照されないobjectを掘り起こしたりしない限り,復元できない.
研究室のGitLabやGitHubのような,SAAS版のリポジトリマネージャを利用している場合,まあまずリモートリポジトリのサーバーにログインなんてできないので,詰んでしまう.
ローカルリポジトリで,このようにどこからも参照されないobjectが発生してしまって,それをもとに戻したい場合は,reflogをたどるか,git fsck --allを使えば良い.
しかしながら,このような浮いたobjectはGC対象となるので,時間が立つと削除され,真に復元不能になる.
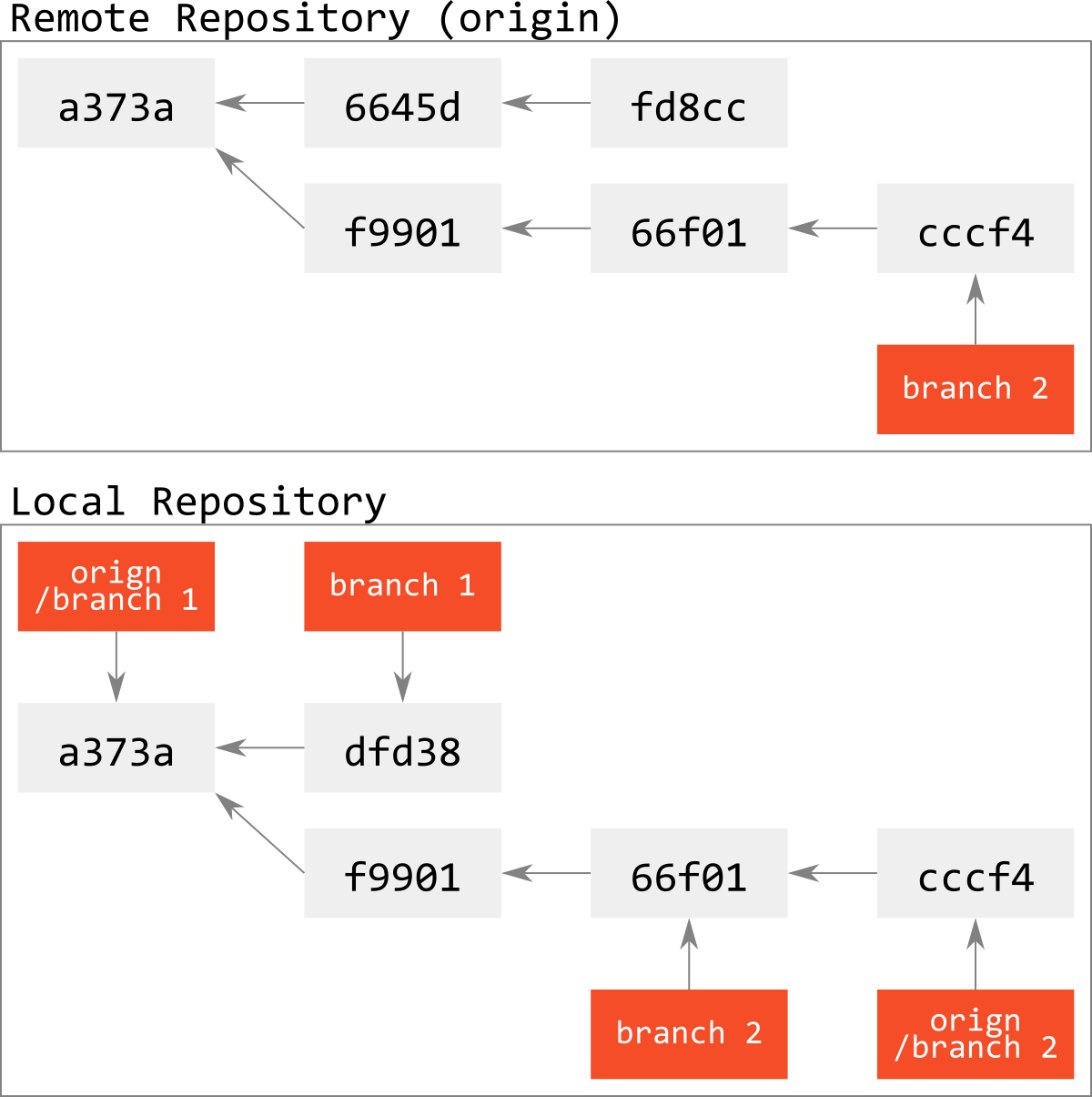
なお,似たような状況は,例えば最初の状態から強制pushでリモートリポジトリのbranch 1を上書きしてしまった場合などにも発生しうる.
この場合は,リモートリポジトリ上にもともとあったbranch 1とは別の歴史のcommit列が登録され,その歴史をbranch 1が参照するようになってしまって,もともとのcommit列はどこからも参照できなくなってしまう.
さらに,リモートリポジトリでは参照不能になってしまったcommitを,誰か別の人がfetchしており,さらにそれに続くcommitを打っていたりすると,DBの不整合が発生し,更にややこしくなってくる.
以上のように,refを上書きしたり削除したりする作業は復元不可能な操作になりうることに注意すること.
何かミスってリモートリポジトリに望ましくない変更を加えてしまったら,早急に管理者へ連絡すること.
今まで見てきたとおり,時間が経つにつれて修正が困難になるし,またGCが走ったりするとそもそも修復不能になる可能性すらある.
あれが理解でいれば,変なことをしようというふうにはなれない,はず.
(実際のコマンドはググればいいし,GUIソフトならそもそもコマンドはいらないし.)
名前
Email (※公開されることはありません)
コメント